在真实场景里,很少只是单一决策,特别是管理决策,往往是连续的。
比如:仓库管理中的库存控制决策,可能每天每一时刻都在做出决策,核心目标是满足需求的同时,把安全库存尽量保持在合理水平。我们要优化的不是某一个时点的决策,而是一段时间内,累积的决策如何达到总体效果最优。
那么,算法要解决的是:为了一个统一目标,如何找到一个策略,让累积的所有决策能够最大化这个统一目标。
为了实现这个,要抽象一些元素和框架出来。
一.基本框架
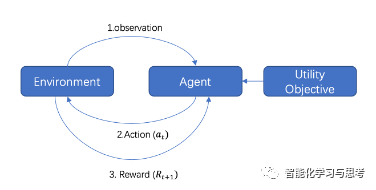
这是前面单一决策使用的图,我们看到智能体先是观察,再是行动,最后系统给出奖励。
如果是序列就要复杂一些:
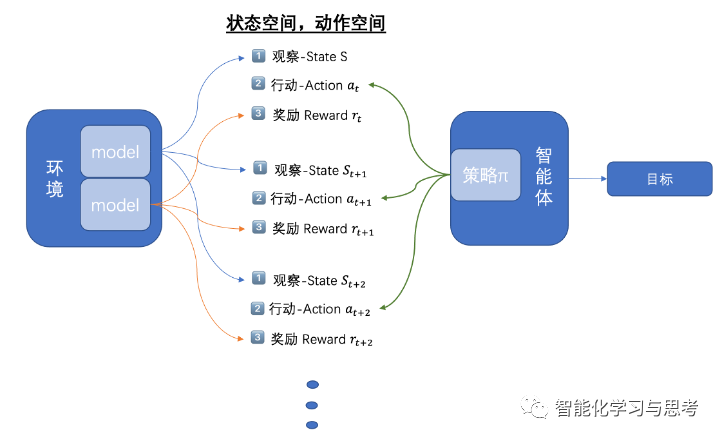
这里面有很多元素,可以分成三个层次来理解它们的意义:
(一)基本元素
首先,智能体观察、判断环境的状态S(State),然后做出一个决策动作a(Action),环境会给智能体一个奖励r(Reward)。
其次,这是一个过程,就是智能体不断观察环境,做出动作,得到奖励的过程。其中,智能体根据环境状态给出动作服从一个总体策略π,就是这些动作背后的决策逻辑不是随机的,是在一整套策略指导下的。
再次,这里有两个机制:一是环境根据智能体的动作给出的奖励机制;二是环境收到智能体的一个动作,从而改变成下一个状态的机制。这两个机制加在一起叫做状态转移模型model。这个很关键,也就是环境如何做出反应。我们大量的不确定性都来自这里。
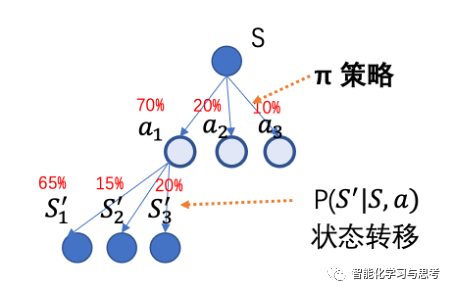
我们拿篮球比赛举例子,当你持球时,整个场上状态为S,你做出了一个决策就是投篮,这个动作一做出,整个场上的状态变为了,从S到如果有一套机制在发挥作用,那么这个机制叫状态转移机制。
(二)价值定义
不要忘了,我们的目标是衡量哪个策略最优,所以要建立最基本的价值评估。
首先是
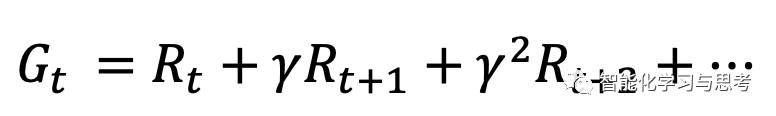
表示智能体如果一直走下去,会得到的奖励总和,但这里需要打一个折扣就是γ
在此,我们介绍一个整个序列决策最重要的概念:状态价值函数
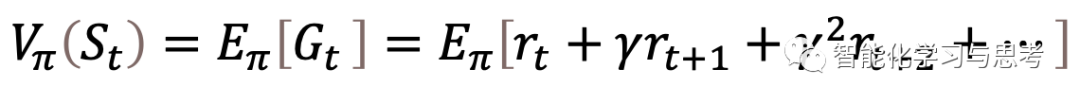
是按照既定策略π行动,在这个状态S以后,每一个可能路径(trajectory)的“总体折扣后价值”的期望。这里注意:1.是折扣后价值,2.是所有可能的路径,3.最重要是期望,也就是所有可能路径得分的平均值。因为,即使确定了π和S;在S位置上是什么a并不确定,那么就不确定,之后更不知道。
这个很反直觉,这里定义一个状态S的价值,不是看它过去的价值,而是说未来的价值可能。
现实中有个比较贴切的例子就是:比如,入职一家公司那个时刻,你对你在这家公司有个期望,可能有上限,也有下限。但平均起来是有一个期望的。
比如,大学毕业进了微软,家人都会为你高兴。虽然这只是一个具体状态,甚至还没踏入微软公司的大门,我们可以认为,不管后续在微软走过什么职业路径,但这个过程还是有一个很高的平均价值。这就是你人生拿到offer这个状态S的V(S),如果你从一入职就遵循一个统一策略,比如,π1(无论如何要生存下去),或者π2(2年之后创业),那么就是Vπ(S),即在这个具体策略下的价值期望。

有本书叫《人类群星闪耀时》,就是写一些伟人在很小的场景里,做出一个很小的动作,对未来产生深远影响,跟这个概念很像。
还拿刚才offer举例子,当你拿到offer了,但有几种动作选择:1.跟同学们大吃二喝买醉三天。2.寻师访友希望找到老师多给一些职场建议。这两个动作选择可能显著影响你未来在微软的整个职业生涯的平均总价值。
(三)求解最优
在这个框架下,主要目标就是训练智能体,为了一个明确的目标,优化其在每个可能状态下的action选择。这个action选择就是π。
如果是这个目的,那么如何定义所谓的最优π,我们称之为?
首先,如何衡量一个π好过另一个?
如果对所有的状态S,都有这个大于等于,我们说π1好于π2

这个例子是希望大家有个直观的理解,但用“生存还是创业”这样的策略显然无法真的选出最优。在具体算法中,这个策略应该是一个具体状态,动作集合,这个跟我们理解的策略不一样,也就是要指导非常具体的在每个可能状态下,最应该做哪件事的指导。相当于一本职场红宝书。

二.算法介绍
(一)基于“贝尔曼最优方程”的动态规划
贝尔曼方程:
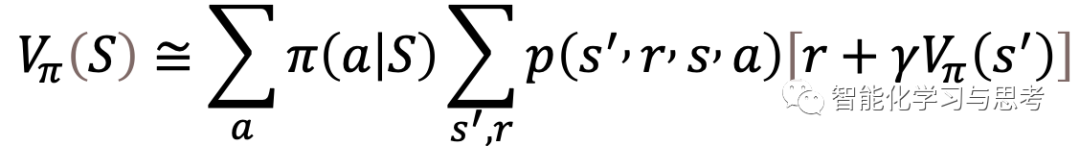
看上去好像非常复杂,其实是在序列决策里,我们能想象到的最理想方式了。它表达了最朴素的对期望的理解。
我们上文说到
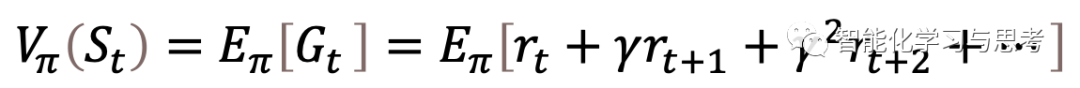
贝尔曼方程就是计算这个
它的含义是把S到这一段尽量说清楚。
1.在S状态下,有多种a的可能,这里就是π(a|S)这个概率。

4.因为是求期望,就是各种概率可能性的总和。这就是贝尔曼方程的含义。
5. 这个方法的最重要的前提是要事先知道这些概率,也就是我们前面提到的两个model状态转移和奖励机制。
贝尔曼最优方程
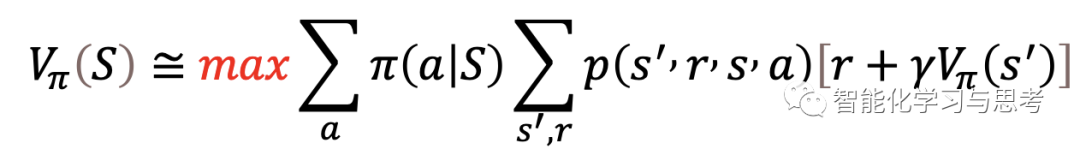
最优策略下各个状态的价值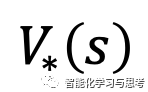 一定等于这个状态下最优动作的期望回报。
一定等于这个状态下最优动作的期望回报。
最重要的就是最优Max,这是在这个状态下所有可能策略选择和状态选择下,那个最优的选择。
所以,贝尔曼最优方程的解法,就是在已知环境变化的情况下,遍历所有的状态和动作组合,找到一个最佳的路径,这个路径下比起其他任何策略、状态、动作都是最优。
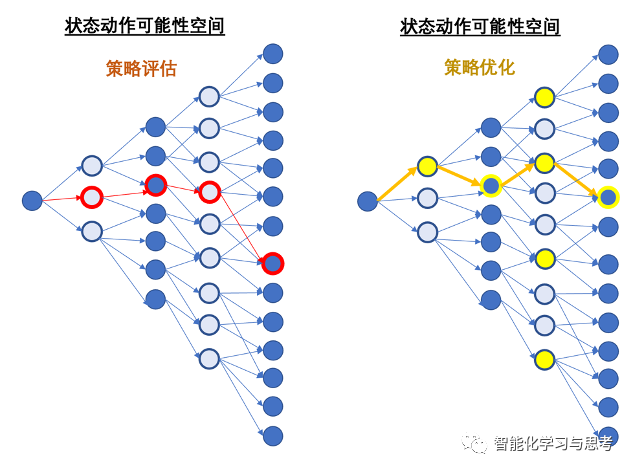
原理理解:
这是一个复杂的迭代算法,但实际上分为两个步骤,一个是要求出各种可能的路线,都有哪些状态,每个状态有可能有哪些动作,以及由此更新的状态价值。这个叫策略评估。
再下一步,优化每一个状态下的动作选择,选择哪些能带来最大价值的动作。这个叫策略优化。
直到,我们找到了在整个状态空间,每一个状态都选择了最佳的动作,而且符合前面提到的最优策略的定义。
举个例子,
比如一场篮球比赛,我们把每个球员的每一次触球都看做一个状态,那么每一个状态都能有一个状态价值。这个触球状态下,都有很多动作选择,如传球、运球、投篮等。那么,如果知道每个动作选择,会给比赛带来的价值,就选择那个最大化可能的值。这样整场比赛,就有了一个最佳动作选择的组合,这就是最优策略。
前提是:
我们知道每个状态下,选择各种动作的概率。
我们知道一旦这个动作触发下一个状态,这个状态的转化概率。
我们知道,这个动作一旦发生,系统给出的奖励概率。
就像一个经验非常丰富的球员,他经过多年训练,完全能够对每次持球做出最合理的判断,知道应该怎么处理。
贝尔曼最优方程就是要通过反复迭代训练,让场上每个球员都能够做出全场看来最优的选择。但条件是,我们知道以上三个前提,这三个前提不止是篮球规则,更是在每个状态下的可能概率。
贝尔曼最优方程就介绍完了,你会发现算法是一种高维语言,寥寥几笔,但背后包含了非常复杂的运算逻辑,从bootstrapping的递归计算,到每个状态节点求最大值,以及这个计算背后的整个假设框架。所以,很多教课书,在介绍算法时,都给出其伪代码,就是用比较直观的编程语言和逻辑复现这个算法。算法和编程语言是非常相同且等价的语言。
贝尔曼最优方程的方法也有巨大的局限性:
1.这种算法需要对环境有非常确定性的了解,每次状态转移概率都要是已知的。这是为什么强化学习在刚开始的突破是在棋类运动。简而言之,你要很了解这个环境,才能算出最优。
2.它的计算量巨大,需要真的遍历几乎所有状态,动作空间。才能真的计算出策略价值和最佳策略。
3.每次计算间隔很长,一次策略评估就要遍历所有状态空间。这对于非常大的状态空间都是巨大的挑战。
(二)基于随机近似的时序差分
随机近似的时序差分方法就为了解决上面的问题的。它有最重要的两个特点就是:
一是model-free,假设对空间不了解,也可以结算。
二是不需要遍历整个状态动作空间。
贝尔曼方程实际上是假设知道状态转移概率,从而可以有比较清晰的通过概率求和的模式求期望(V(S))。随机近似的基本思想是,如果我不能知道这个环境的model,我换个逻辑求这个期望(V(S))。
看下公式
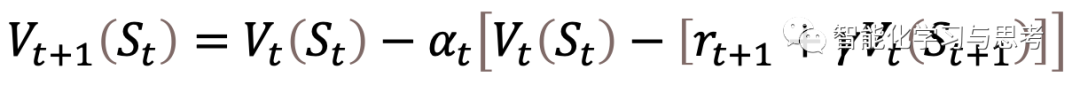
不要被这个式子所困扰,我们只需要知道这个式子核心要表达的意思就可以了,在这之前,要对它有一个基本的理解:

如果贝尔曼最优方程的方法是非常反直觉的,那么这种随机近似的时序差分,就是很类似我们人类学习的逻辑了,它是先有个假设,然后不断根据现实情况更新。但这里当然继承了贝尔曼方法的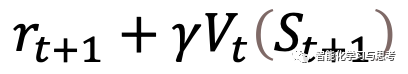 。
。
比如,打篮球,刚开始都是一脸懵懂的,不会投篮不知道传球不会运球,但随着各种经验慢慢学习和体会,水平就会越来越高。
随机近似的时序差分方法,有很多算法都鼎鼎大名,比如:Q-learning,Q-learning利用随机近似逻辑直接计算最优的动作价值,相当于把策略评估策略优化在随机近似的逻辑下同时完成。
当然,随机近似的时序差分算法,也有一定局限性,主要体现在当面对连续空间时稍显吃力。连续空间可以把它抽象成离散,但当连续空间非常大时,实际计算为了达到准确,需要存储大量状态信息。这在算力上又成了困扰。
为了更好的理解时序差分,我们做一个比喻,假如这个算法是一个在宇宙中挖矿的飞船,那么遵循贝尔曼最优方程的这个飞船应该长这样。

它是在一个非常固定环境下执行操作的挖矿机,对环境了如指掌,对环境可能出现的问题也非常清楚,虽然在每个点上仍然需要独立做出决定,但核心目标是追求效率。
那么,随机近似时序差分的这个飞船就没这么幸运,它要解决的最重要的问题是如何平衡开采效率和有效探索。
在有些逐渐清晰的环境里,要充分利用已经掌握的信息加快开采;但只是这些矿石远远不够,它还要分出一部分资源继续探索新的可能性。

(三)从tabular到函数
无论贝尔曼还是随机近似,其计算核心都是离散状态下,每个s对应a的那个价值。
我们是默认通过一个表格来一一对应的,我们叫做q-table。

就是有多少个s状态,对应可能有多少动作a,那么就有多少q(s,a)
但是现实中很多场景s状态和a状态是非常多的,存储量巨大。另外,有些场景是连续的,不是离散的,这个就更麻烦。所以,这个表格类的表达方式有很大局限。
解决这个问题的方法就是函数,这是一个非常重要的数学思想。
就是我们如果想描绘两个变量之间的关系,如果有现成的数据最好,比如q-table。如果没有最好的方法就是建立这两个变量之间的函数关系y=f(x)。
y=f(x),可盐可甜,可以表示离散,也绝对可以表示连续,而且有大把的方法来通过学习训练数据拟合这个f()出来。这个两个变量可以线性的y=ax+b,也可以是二次函数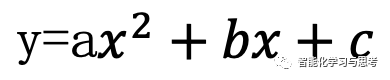 ,如果你不知道可能的函数结构,也可以用神经网路的方式来拟合。前面我们提到的Q-learning,时下最流行的强化学习算法DQN,其实就是在神经网络拟合q-talbe的Q-learning算法。
,如果你不知道可能的函数结构,也可以用神经网路的方式来拟合。前面我们提到的Q-learning,时下最流行的强化学习算法DQN,其实就是在神经网络拟合q-talbe的Q-learning算法。

这种图形象地描绘出了Deep Q-learning的计算过程,每个正方形就是一个q(S),有很多细线连接到它,那是神经网络根据具体光电(数据)计算出它的值,但每个正方形q(S)又在算法里迭代更新。
还用在宇宙中采矿飞船举例,那么函数算法飞船,基本上是一个可以自动驾驶的飞船。
之前优化的决策点是,在哪采矿怎么采,以及如果继续探索,探寻计划是什么?这个优化的决策主体可能是飞船的核心采矿团队。
现在优化除了采矿以外,就连飞船每一个连续飞行动作都可以优化。相当于自动驾驶的采矿飞船。

三.总结
以上介绍的三个算法不是完全独立的,这些算法是层层递进的。
虽然各种算法不断更替,但贝尔曼方程的Bootstrapping的思想一直是核心,它提供了一套可以用来把先用奖励+估计未来奖励的迭代计算。
在随机近似时序差分的框架里,解决了当环境模型不起作用下,如何计算期望的问题。DQN的横空出世,是对于Q-table函数化这个数学思想,被引入之后的事情。
其实,对于序列决策算法的演化,远未停止。
由于篇幅限制,我们只介绍了三层,但现在最新的算法是从求状态价值到直接去优化策略函数,相当于更集成、更并行的计算。如果最早的贝尔曼是要试图对整个环境了如指掌,才能算出最优,那么actor-critic算法,就是只针对现有情况自己和自己博弈,从经验不断精进,做到最大限度的适应环境。
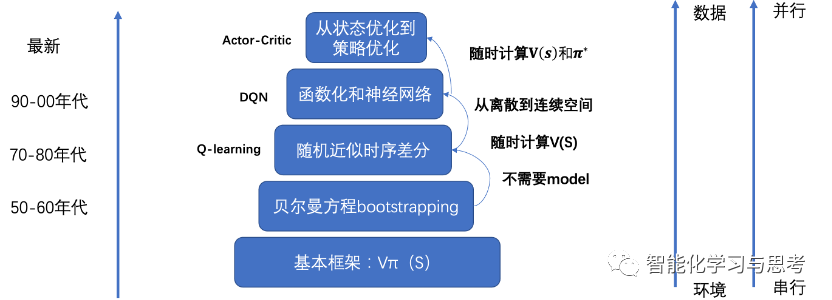
这里之所以花这么大篇幅从古老的算法讲起,是因为,如果不介绍清楚这个发展演进框架,直接看actor-critic算法基本是一头雾水,而且这样大家可以更立体地理解算法背后的逻辑。
这个算法演进过程的主线,是对数学方法和数学思想的排列组合应用,是发现问题解决问题的过程,是计算资源快速扩大的表现,也是强化学习从理论研究逐步到实际应用的过程。按理说actor-critic算法应该早就有理论基础,但它的出现就是算力和实际应用快速地推动的。

0
推荐
 京公网安备 11010502034662号
京公网安备 11010502034662号 {kind=link}